Once you set the ODBC Variables and Paths at Linux Machine and testing is done.. you need to restart the informatica service
TDExpress15.00.01_Sles10:~ #
TDExpress15.00.01_Sles10:~ # cd /var/opt/teradata/informatica/server/tomcat
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/server/tomcat # cd bin/
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/server/tomcat/bin # ls
infaservice.sh
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/server/tomcat/bin # ./infaservice.sh shutdown
Stopping Informatica services on node 'node01_tdgogate'
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/server/tomcat/bin # ./infaservice.sh startup
Starting Informatica services on node 'node01_tdgogate'
Using CURRENT_DIR: /var/opt/teradata/informatica/tomcat/bin
Using INFA_HOME: /var/opt/teradata/informatica
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/server/tomcat/bin #
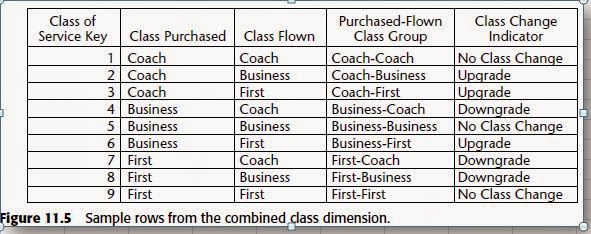
Part - 1
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # ls
ssgodbc.linux64
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # ./ssgodbc.linux64
Usage: ssgodbc -d dsn -u username -p password [-t user] [-v] [-g]
-d Data Source Name
-u odbc username
-p odbc password
-v verbose output
-c column description only
-g get array size only
-t time SQLTablesW for user
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # ./ssgodbc.linux64 -d DBC -u dbc -p dbc -v
Error for thread 0
{error} STATE=IM003, CODE=46909632806912, MSG=[DataDirect][ODBC lib] Specified driver could not be loaded
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # vi /var/opt/teradata/informatica/ODBC7.0/odbc.ini
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # vi /var/opt/teradata/informatica/ODBC7.0/lib/
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # cd /var/opt/teradata/informatica/ODBC7.0/lib/
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/ODBC7.0/lib # ls
DWase26r.so DWdb226.so DWifcl26r.so DWmsss26.so DWmysql26.so DWora26.so DWsqls26.so DWtera26s.so libDWmback.so libodbcinst.so vscnctdlg.so
DWase26.so DWgplm26r.so DWifcl26.so DWmsss26s.so DWoe26.so DWpsql26r.so DWtera26r.so DWtrc26.so libDWmbackw.so libodbc.so
DWdb226r.so DWgplm26.so DWmsss26r.so DWmsssdlg26.so DWora26r.so DWpsql26.so DWtera26.so libDWicu26.so libDWssl26.so odbccurs.so
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/ODBC7.0/lib # find / -name "tdat.so
>
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/ODBC7.0/lib # find / -name "tdata.so"
/opt/teradata/client/.ODBC_32_PRE130_BRIDGE/drivers/tdata.so
/opt/teradata/client/.ODBC_64_PRE130_BRIDGE/drivers/tdata.so
/opt/teradata/client/15.00/odbc_32/lib/tdata.so
/opt/teradata/client/15.00/odbc_64/lib/tdata.so
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/ODBC7.0/lib # vi /var/opt/teradata/informatica/ODBC7.0/odbc.ini
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/ODBC7.0/lib # cd /var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # ./ssgodbc.linux64 -d DBC -u dbc -p dbc -v
Connected
ODBC version = -03.52.0000-
DBMS name = -Teradata-
DBMS version = -15.00.0101 15.00.01.01-
Driver name = -tdata.so-
Driver version = -15.00.00.03-
Driver ODBC version = -03.51-
Enter SQL string: select 1 from dual;
Error for thread 0
{error} STATE=37000, CODE=46913927770501, MSG=[Teradata][ODBC Teradata Driver][Teradata Database] Syntax error, expected something like a name or a Unicode delimited identifier or an 'UDFCALLNAME' keyword or '(' between the 'from' keyword and the 'dual' keyword.
Enter SQL string: sel 1;
1
1
TDExpress15.00.01_Sles10:~ #
TDExpress15.00.01_Sles10:~ # cd /var/opt/teradata/informatica/server/tomcat
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/server/tomcat # cd bin/
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/server/tomcat/bin # ls
infaservice.sh
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/server/tomcat/bin # ./infaservice.sh shutdown
Stopping Informatica services on node 'node01_tdgogate'
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/server/tomcat/bin # ./infaservice.sh startup
Starting Informatica services on node 'node01_tdgogate'
Using CURRENT_DIR: /var/opt/teradata/informatica/tomcat/bin
Using INFA_HOME: /var/opt/teradata/informatica
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/server/tomcat/bin #
Part - 1
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # ls
ssgodbc.linux64
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # ./ssgodbc.linux64
Usage: ssgodbc -d dsn -u username -p password [-t user] [-v] [-g]
-d Data Source Name
-u odbc username
-p odbc password
-v verbose output
-c column description only
-g get array size only
-t time SQLTablesW for user
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # ./ssgodbc.linux64 -d DBC -u dbc -p dbc -v
Error for thread 0
{error} STATE=IM003, CODE=46909632806912, MSG=[DataDirect][ODBC lib] Specified driver could not be loaded
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # vi /var/opt/teradata/informatica/ODBC7.0/odbc.ini
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # vi /var/opt/teradata/informatica/ODBC7.0/lib/
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # cd /var/opt/teradata/informatica/ODBC7.0/lib/
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/ODBC7.0/lib # ls
DWase26r.so DWdb226.so DWifcl26r.so DWmsss26.so DWmysql26.so DWora26.so DWsqls26.so DWtera26s.so libDWmback.so libodbcinst.so vscnctdlg.so
DWase26.so DWgplm26r.so DWifcl26.so DWmsss26s.so DWoe26.so DWpsql26r.so DWtera26r.so DWtrc26.so libDWmbackw.so libodbc.so
DWdb226r.so DWgplm26.so DWmsss26r.so DWmsssdlg26.so DWora26r.so DWpsql26.so DWtera26.so libDWicu26.so libDWssl26.so odbccurs.so
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/ODBC7.0/lib # find / -name "tdat.so
>
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/ODBC7.0/lib # find / -name "tdata.so"
/opt/teradata/client/.ODBC_32_PRE130_BRIDGE/drivers/tdata.so
/opt/teradata/client/.ODBC_64_PRE130_BRIDGE/drivers/tdata.so
/opt/teradata/client/15.00/odbc_32/lib/tdata.so
/opt/teradata/client/15.00/odbc_64/lib/tdata.so
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/ODBC7.0/lib # vi /var/opt/teradata/informatica/ODBC7.0/odbc.ini
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/ODBC7.0/lib # cd /var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64
TDExpress15.00.01_Sles10:/var/opt/teradata/informatica/tools/debugtools/ssgodbc/linux64 # ./ssgodbc.linux64 -d DBC -u dbc -p dbc -v
Connected
ODBC version = -03.52.0000-
DBMS name = -Teradata-
DBMS version = -15.00.0101 15.00.01.01-
Driver name = -tdata.so-
Driver version = -15.00.00.03-
Driver ODBC version = -03.51-
Enter SQL string: select 1 from dual;
Error for thread 0
{error} STATE=37000, CODE=46913927770501, MSG=[Teradata][ODBC Teradata Driver][Teradata Database] Syntax error, expected something like a name or a Unicode delimited identifier or an 'UDFCALLNAME' keyword or '(' between the 'from' keyword and the 'dual' keyword.
Enter SQL string: sel 1;
1
1
Part - 2 --/etc/bash.bashrc
if test -n "$SSH_CLIENT" -a -z "$PROFILEREAD" ; then
. /etc/profile > /dev/null 2>&1
fi
if test "$is" != "ash" ; then
#
# And now let's see if there is a local bash.bashrc
# (for options defined by your sysadmin, not SuSE Linux)
#
test -s /etc/bash.bashrc.local && . /etc/bash.bashrc.local
fi
TMP=/tmp; export TMP
TMPDIR=$TMP; export TMPDIR
ORACLE_HOSTNAME=tdgogate; export ORACLE_HOSTNAME
ORACLE_UNQNAME=orcl; export ORACLE_UNQNAME
ORACLE_BASE=/var/opt/teradata/oracle; export ORACLE_BASE
ORACLE_HOME=$ORACLE_BASE/product/11.2.0/db_1; export ORACLE_HOME
TERADATA_HOME=/opt/teradata/client/15.00/odbc_64/lib; export TERADATA_HOME
ODBCINI=/var/opt/teradata/informatica/ODBC7.0/odbc.ini; export ODBCINI
ORACLE_SID=orcl; export ORACLE_SID
PATH=/usr/sbin:$PATH; export PATH
PATH=$ORACLE_HOME/bin:$PATH; export PATH
ODBCHOME=/var/opt/teradata/informatica/ODBC7.0; export ODBCHOME
PATH=/var/opt/teradata/informatica/tomcat/bin:/var/opt/teradata/informatica/server/bin:/var/opt/teradata/informatica/tomcat/server/lib:$ODBCHOME/bin:$TERADATA_HOME/bin:$PATH; export PATH;
LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib:/var/opt/teradata/informatica/tomcat/server/bin/:$ODBCHOME/lib; export LD_LIBRARY_PATH
CLASSPATH=$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib; export CLASSPATH
INFRA_CODEPAGENAME=UTF-8; export INFRA_CODEPAGENAME
LANG=en_US.utf8; export LANG
LC_ALL=en_US.utf8; export LC_ALL
Part - 3 : entries in odbc.ini --
[ODBC Data Sources]
SQL Server Legacy Wire Protocol=DataDirect 7.0 SQL Server Legacy Wire Protocol
DB2 Wire Protocol=DataDirect 7.0 DB2 Wire Protocol
Informix Wire Protocol=DataDirect 7.0 Informix Wire Protocol
Oracle Wire Protocol=DataDirect 7.0 Oracle Wire Protocol
Sybase Wire Protocol=DataDirect 7.0 Sybase Wire Protocol
Teradata=DataDirect 7.0 Teradata
SQL Server Wire Protocol=DataDirect 7.0 SQL Server Wire Protocol
MySQL Wire Protocol=DataDirect 7.0 MySQL Wire Protocol
PostgreSQL Wire Protocol=DataDirect 7.0 PostgreSQL Wire Protocol
Greenplum Wire Protocol=DataDirect 7.0 Greenplum Wire Protocol
Progress OpenEdge Wire Protocol=DataDirect 7.0 Progress OpenEdge Wire Protocol
default=tdata.so
DBC=tdata.so
[ODBC]
IANAAppCodePage=4
InstallDir=/var/opt/teradata/informatica/ODBC7.0
Trace=1
TraceFile=odbctrace.out
TraceDll=/var/opt/teradata/informatica/ODBC7.0/lib/DWtrc26.so
[DBC]
Driver=/opt/teradata/client/15.00/odbc_64/lib/tdata.so
Description=DataDirect 7.0 Teradata
AccountString=
AuthenticationDomain=
AuthenticationPassword=
AuthenticationUserid=
CharacterSet=ASCII
DBCName=dbc
Database=dbc
EnableDataEncryption=0
EnableExtendedStmtInfo=0
EnableLOBs=1
EnableReconnect=0
IntegratedSecurity=0
LoginTimeout=20
LogonID=dbc
MapCallEscapeToExec=0
MaxRespSize=8192
Password=
PortNumber=1025
PrintOption=N
ProcedureWithSplSource=Y
ReportCodePageConversionErrors=0
SecurityMechanism=
SecurityParameter=
ShowSelectableTables=1
TDProfile=
TDRole=
TDUserName=
And all above this will be available in details on -- https://www.youtube.com/watch?v=YyDOxbwRi0k
Follow the exact steps mentioned in video..