In earlier post we have seen how can we delete the records from relational target
http://gyaankatta.blogspot.in/2014/06/deleting-duplicate-records-from.html
However, deleting a record from Flat File target is not that simple.
Why -- If we do not select option - Append If Exists - at Flat File target, informatica will delete the contents of the flat file at start of the mapping itself. So, if we do the implementation as we seen in our earlier post, it will read and insert 0 records and ultimately at file we will have 0 records.
Also, if we select the option - Append If Exits - it will just append all incoming records, instead of updation or deletion.
Apart from that, if you try to use Update Strategy with DD_Delete, still it won't work on Flat File as a target and all records will always get inserted.
How -- To achieve the desired output, we will read the content of the file in some dummy file and again process the dummy file for deleting the duplicate records.
Source Records before running the workflow
[oracle@gogate Informatica]$ cat emp.txt
id,name
1,mandar
2,sudhir
3,ashish
4,sakshi
3,ashish
3,ashish
3,ashish
3,ashish
3,ashish
3,ashish
3,ashish
2,sudhir
3,ashish
4,sakshi
1,mandar
1. Using command task, we will first create a dummy file of an actual source file from where we have to delete the duplicate records.

Below unix command we will specify at command task to create a dummy file at same directory where the original file resides
less /u01/app/oracle/Informatica/emp.txt > /u01/app/oracle/Informatica/emp_bkp.txt
2. We will create a second session, which will read dummy file instead of an original file.
a. Here, to duplicate record removal logic will be different that of relational table. As in a flat file, all records will get deleted first place [at start of a session], we just have to insert the unique records.
b. To eliminate the duplicate records from target we have number of ways as we discussed in earlier post. However in this case we will go with Aggregator Transformation, and will select Group By ports for both columns.
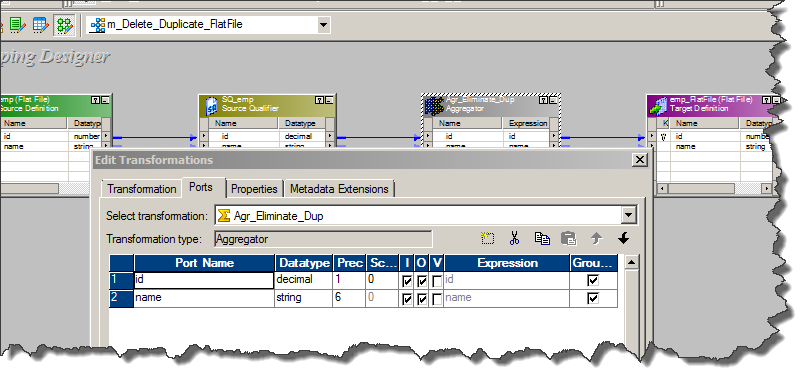 c. Aggregator Transformation itself will remove all duplicate rows and we will directly connect all incoming ports to Flat File target.
c. Aggregator Transformation itself will remove all duplicate rows and we will directly connect all incoming ports to Flat File target.
Records after executing the workflow
[oracle@gogate Informatica]$ cat emp.txt
2,sudhir
3,ashish
4,sakshi
1,mandar
Below is the whole mapping and workflow structure..


http://gyaankatta.blogspot.in/2014/06/deleting-duplicate-records-from.html
However, deleting a record from Flat File target is not that simple.
Why -- If we do not select option - Append If Exists - at Flat File target, informatica will delete the contents of the flat file at start of the mapping itself. So, if we do the implementation as we seen in our earlier post, it will read and insert 0 records and ultimately at file we will have 0 records.
Also, if we select the option - Append If Exits - it will just append all incoming records, instead of updation or deletion.
Apart from that, if you try to use Update Strategy with DD_Delete, still it won't work on Flat File as a target and all records will always get inserted.
How -- To achieve the desired output, we will read the content of the file in some dummy file and again process the dummy file for deleting the duplicate records.
Source Records before running the workflow
[oracle@gogate Informatica]$ cat emp.txt
id,name
1,mandar
2,sudhir
3,ashish
4,sakshi
3,ashish
3,ashish
3,ashish
3,ashish
3,ashish
3,ashish
3,ashish
2,sudhir
3,ashish
4,sakshi
1,mandar
1. Using command task, we will first create a dummy file of an actual source file from where we have to delete the duplicate records.
Below unix command we will specify at command task to create a dummy file at same directory where the original file resides
less /u01/app/oracle/Informatica/emp.txt > /u01/app/oracle/Informatica/emp_bkp.txt
2. We will create a second session, which will read dummy file instead of an original file.
a. Here, to duplicate record removal logic will be different that of relational table. As in a flat file, all records will get deleted first place [at start of a session], we just have to insert the unique records.
b. To eliminate the duplicate records from target we have number of ways as we discussed in earlier post. However in this case we will go with Aggregator Transformation, and will select Group By ports for both columns.
Records after executing the workflow
[oracle@gogate Informatica]$ cat emp.txt
2,sudhir
3,ashish
4,sakshi
1,mandar
Below is the whole mapping and workflow structure..













