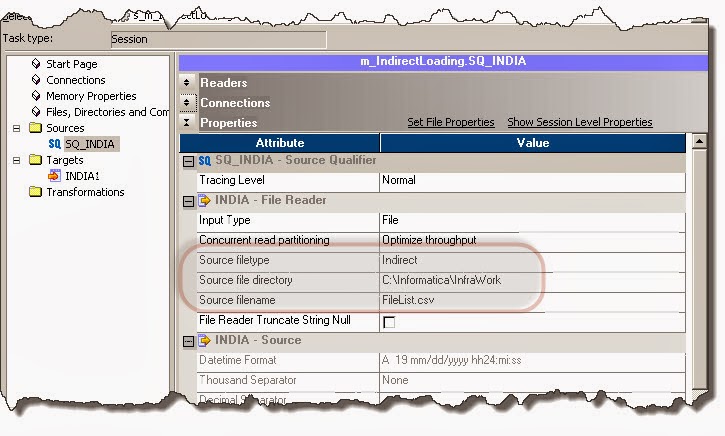
This question came to my mind, when I came across one data issue in prod environment. Our BO Tool was generating 3 queries - I am assuming there were different context defined at universe - and filter which user had choose at Query level was actually getting applied only for one Query. User was expecting to filter some records, however - as filter was getting applied to only one query - at report level user was getting all records with null values.
Lets re-create the same scenario as below
In our earlier post http://gyaankatta.blogspot.in/2013/10/business-objects-universe-design_9960.html we had seen how you can create a Context at universe.
We will use same example now.
We have defined 2 context in our earlier post
1. To get Salary for each Employee, so joining Employee Fact and Emp and Dep dimentions.
2. To get Salary for each Departments, so joining Departments Fact and Dep Dimension.
At universe level, your joins will be as below

As you can see, we have 2 Contexts defined and Respective joins for it.
Report Requirement
We have to generate report, which will give Department_Name, Employee_Name, Salary_Per_Employee and Salary_Per_Department having Salary_Per_Department less than 15000.
You will choose your objects at BO Query Panel as below

You have pulled Salary_Per_Department condition in your BO Query. If you refresh the report, you will expect that your report should give you all Departments and Employees having salary less than 15000.
However, your reports will give all records and no record will get filtered out.
Why is so ?
If we verify 2 queries generated by BO, filter conditions which we have specified will get applied only to one Query as below
 This is a query one, generated by context Department and Employee_Fact. This one do not have filter condition which user is expecting to add.
This is a query one, generated by context Department and Employee_Fact. This one do not have filter condition which user is expecting to add.

This is a Query2, from Context Department and Department_Fact and this is having filter condition which user has specified.
BO tool will do FULL OUTER JOIN of the results generated from above 2 queries.
Second query will filter all departments having salary less than 15000, however first query won't do that. So, at final results, user can see all departments.
Is this because user added Fact as a Filter Condition?
No, its not because of that. Lets add one more table - Location - at Universe using same structure.
 As you see here, we have added LOCATIONS table and all columns from this table we have exposed to Universe as Dimensions.
As you see here, we have added LOCATIONS table and all columns from this table we have exposed to Universe as Dimensions.
Save the universe, and now generate same query again, with filter condition as City = 'Bombay' as below
 In earlier example, we have added filter which was a Fact, however this time its a pure Dimension. Same as earlier, BO Tool will generate 3 queries depending upon the context.
In earlier example, we have added filter which was a Fact, however this time its a pure Dimension. Same as earlier, BO Tool will generate 3 queries depending upon the context.
 Query 1 got generated using the first context of Employee_FACT and Employee_DIM.
Query 1 got generated using the first context of Employee_FACT and Employee_DIM.
 Query 2 got generated using context Departments_FACT and Departments
Query 2 got generated using context Departments_FACT and Departments
 Query 3 got generated using context Departments_FACT and Departments
Query 3 got generated using context Departments_FACT and Departments
As you can see, Dimension filter which we have added at BO Query got applied only for one query out of three. So at ultimate report, you will get all records but not specific to City as Bombay.
This situation will occur only when you give your universe for Ad-Hoc reporting. In case of Canned Report you do not have to worry.
Remedy / Workaround --
Even I am not sure the workaround of it. however hoping to get something related to it.
Lets re-create the same scenario as below
In our earlier post http://gyaankatta.blogspot.in/2013/10/business-objects-universe-design_9960.html we had seen how you can create a Context at universe.
We will use same example now.
We have defined 2 context in our earlier post
1. To get Salary for each Employee, so joining Employee Fact and Emp and Dep dimentions.
2. To get Salary for each Departments, so joining Departments Fact and Dep Dimension.
At universe level, your joins will be as below

Report Requirement
We have to generate report, which will give Department_Name, Employee_Name, Salary_Per_Employee and Salary_Per_Department having Salary_Per_Department less than 15000.
You will choose your objects at BO Query Panel as below

You have pulled Salary_Per_Department condition in your BO Query. If you refresh the report, you will expect that your report should give you all Departments and Employees having salary less than 15000.
However, your reports will give all records and no record will get filtered out.
Why is so ?
If we verify 2 queries generated by BO, filter conditions which we have specified will get applied only to one Query as below


This is a Query2, from Context Department and Department_Fact and this is having filter condition which user has specified.
BO tool will do FULL OUTER JOIN of the results generated from above 2 queries.
Second query will filter all departments having salary less than 15000, however first query won't do that. So, at final results, user can see all departments.
Is this because user added Fact as a Filter Condition?
No, its not because of that. Lets add one more table - Location - at Universe using same structure.

Save the universe, and now generate same query again, with filter condition as City = 'Bombay' as below




As you can see, Dimension filter which we have added at BO Query got applied only for one query out of three. So at ultimate report, you will get all records but not specific to City as Bombay.
This situation will occur only when you give your universe for Ad-Hoc reporting. In case of Canned Report you do not have to worry.
Remedy / Workaround --
Even I am not sure the workaround of it. however hoping to get something related to it.












































{kind=link}